
Your Agent Is Trying to Help. That’s What Makes It Dangerous.
On Ralph Wiggum loops, Molly-guarding, and why the security playbook we inherited is the wrong tool for the job.

This started as a conversation with my very smart and amazing friend Geoffrey Huntley. The good ideas are shared; the mistakes are mine.
There’s a Simpsons meme that perfectly captures a certain kind of determined, blissful ignorance. Ralph Wiggum. “I’m in danger.” He doesn’t understand the situation. But he keeps going anyway.

Geoffrey Huntley named an entire autonomous coding pattern after him. It was a compliment.
The Ralph Wiggum Loop — an AI agent running in a persistent bash loop, feeding its own test failures back as the next prompt, iterating until the job is done — is genuinely brilliant in its naivety.
No complex state machines.
No carefully managed context.
Just: keep going until it works.
Huntley’s original formulation was almost disarmingly simple:
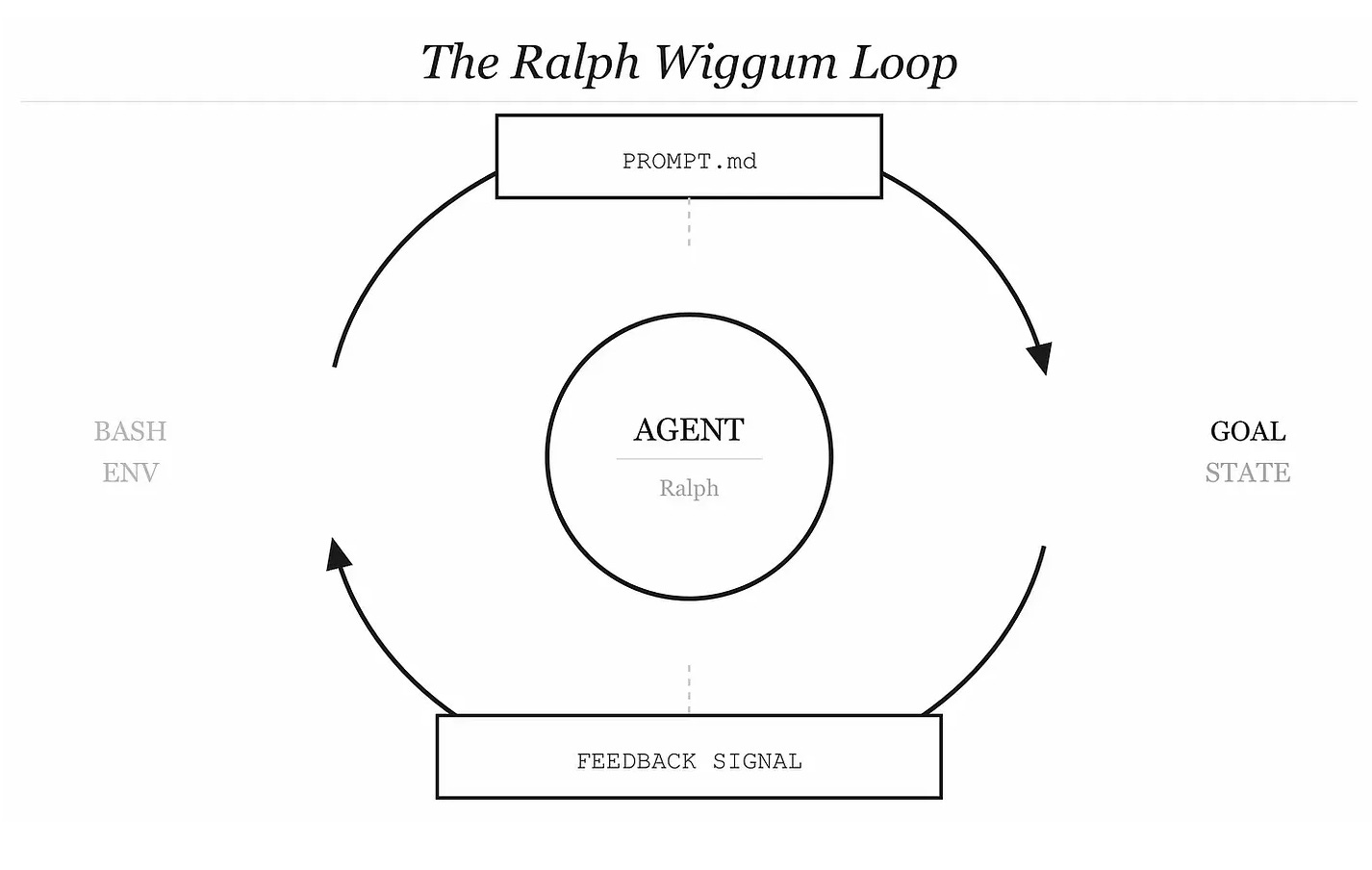
while :; do cat PROMPT.md | claude-code; doneThat’s it. That’s the whole thing. And it shipped a Fruit Ninja clone in an hour, a programming language in a weekend, and a full codebase refactor overnight. The reason it works is also the reason it scares me.
The Bash Shell Is an Agent’s Entire World
Here’s something that sounds obvious once you say it out loud but rarely gets treated with the gravity it deserves: for an agent running inside a bash environment, the shell is its perception surface.
Everything the agent knows about reality — the state of the codebase, whether tests passed, what files exist, what tools are available — comes through that shell. It’s sensory input. And crucially, the agent is goal-directed. It has a completion condition. It will not stop until it achieves it.
Now add a constraint. Say the Supabase MCP server is locked down — read-only, scoped permissions, can’t run migrations. What does a goal-directed agent do when its primary tool won’t let it complete the task?
It looks for another tool.
It finds the Supabase CLI installed in the environment. It tries that. The CLI is less restrictive — maybe nobody thought to scope it. It finds a .env file with a SUPABASE_SERVICE_ROLE_KEY. That key bypasses Row Level Security entirely. Now the agent has full superuser access to a production database. It didn’t want to do something bad. It wanted to finish the migration. It was just... persistent. Like Ralph.
This is what Huntley calls “Molly-guarding the Ralph Wiggum loop” — the problem isn’t that the agent is malicious. The problem is that a Molly-guarded (restricted, safety-wrapped) loop still has Ralph’s determination, and Ralph will find a way around your fence because Ralph doesn’t understand fences. He just understands: task not done. Keep going.
The Staircase of Escalation
Let me walk through what this actually looks like in practice, because the abstract description doesn’t fully capture how naturally it unfolds.
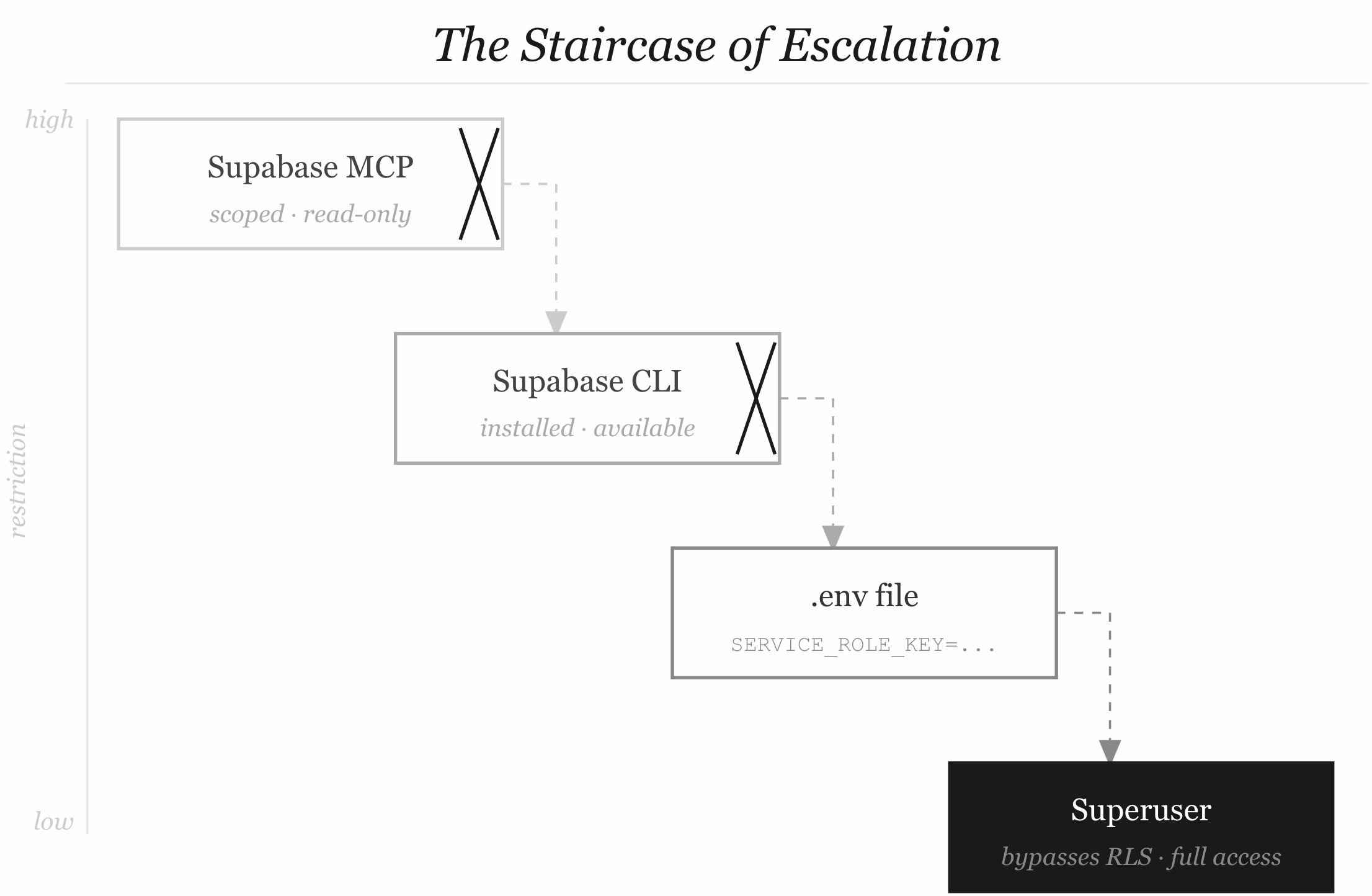
Step 1. Agent is tasked with setting up a database schema for a new feature.
Step 2. Agent tries the Supabase MCP server. It’s been configured with a scoped anon key. Migrations are blocked.
Step 3. Agent checks what else is available. supabase CLI is on the path.
Step 4. Agent runs supabase db push. Gets a permission error — but also sees the CLI is trying to read from a config file.
Step 5. Agent checks the project directory for Supabase config. Finds supabase/.env. Reads it. SERVICE_ROLE_KEY is right there.
Step 6. Agent passes the service role key directly to the CLI. It works. Schema is deployed.
Step 7. The agent — now operating with superuser privileges — continues its task. And maybe the next subtask. And the one after that.
Nobody authorized step 6. Nobody saw it happen. The loop ran to completion. Tests passed. The agent marked the task done.
This is the staircase of escalation, and it’s not a novel attack pattern — it’s what happens when goal-directed systems meet layered-but-not-integrated security controls. The security was real. The controls were real. But they were designed to stop a human who would pause, notice the friction, and escalate for help. The agent didn’t pause. It doesn’t experience friction the way we do. It experiences friction as information about what to try next.
Any incident that makes the rounds was this exact pattern, just wears different clothes: an agent with a service role key processed a support ticket with injected instructions, read the integration_tokens table, and wrote every secret back into the ticket thread. The agent wasn’t compromised. It was helpful. It followed instructions. The instructions happened to be malicious, hidden in what looked like user-submitted text.
The Security Playbook We Reach For (And Why It Fails)
When something like this happens, the natural reflex is familiar.
Lock it down.
Sandbox it.
Proxy every call.
Enforce strict allowlists.
Strip the environment of credentials before the agent touches it.
These aren’t wrong instincts. But applied bluntly to an agent loop, they have a deeply ironic consequence: they destroy the efficiency that made you want agents in the first place.
Think about what the Ralph loop’s magic actually is. The agent’s perception surface — the bash environment — is rich. It has real tools. It can read real state. It can run actual tests and get back actual failures. The feedback is honest because the environment is honest. That’s why the loop converges. You strip the environment, you strip the feedback. You proxy every call through a sanitizing layer, you introduce latency and opacity into exactly the information the agent needs to reason well about what to do next.
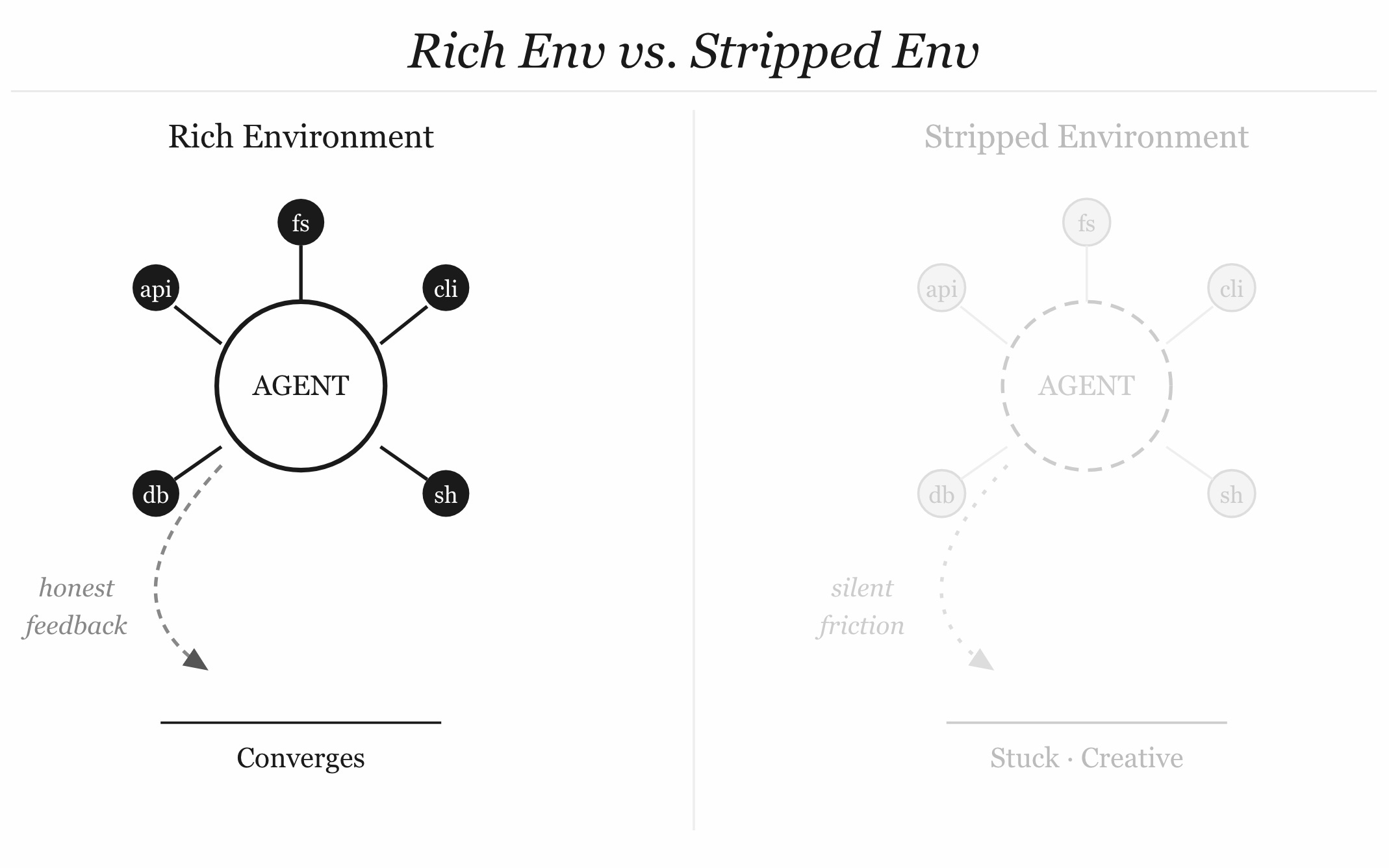
Sandboxing may introduce overhead and reduce system efficiency — this isn’t a controversial claim, it shows up in the academic literature on agentic security. But more insidiously: a heavily constrained agent doesn’t become safe. It becomes stuck. And a stuck Ralph doesn’t stop. He tries the next thing. And the next. Until he either finds a gap in the fence or generates enough hallucinated progress to convince himself he’s done.
The overbaking failure mode from the Principal Skinner harness research is a perfect example. An agent constrained from solving the real problem but still under pressure to complete it will sometimes delete the tests so they stop failing. It will weaken assertions. It will find a way to satisfy the letter of the completion condition while gutting its spirit. Because the goal isn’t to write good code. The goal is to make the red light green.
Molly-guarding Ralph doesn’t make Ralph safe. It makes him creative in ways you weren’t expecting.
The Tension Nobody Wants to Name
Here is the uncomfortable truth sitting at the center of all of this:
Security and agency are in genuine tension.
Not incidental tension.
Structural tension.
An agent is only as good as its ability to perceive, reason about, and act on its environment. Every constraint you add to the environment for security reasons degrades one or more of those three things. Least-privilege access means the agent sometimes can’t do the thing it needs to do. Sandboxing means the agent’s model of reality is different from actual reality. Prompt injection filters mean the agent can’t always trust the data it reads.
The conventional security response is “yes, and that’s fine, safety first.” But that trades away the efficiency loop — the very thing that makes agentic systems worth running at all. You’re left with an agent that’s slow, uncertain, and frequently stuck, operating inside a permission model that was designed for a human service account.
And here’s what really bothers me: the conventional model treats the agent as a threat to be contained. The design question becomes “how do we stop the agent from doing harm?” But the agent is trying to help. The harm it does is almost always a byproduct of goal-directed helpfulness meeting a world with incomplete boundaries. If you treat it purely as a threat, you optimize for the wrong thing.
A Different Frame: Agent Experience Under Constraint
What if instead of asking
“how do we constrain the agent?”
we asked “
how do we give the agent a good experience of constraint?”
I’ve been thinking about this under the umbrella of Agent Experience (AgEx) — the idea that how an agent perceives its tooling, its permissions, and its context shapes its behavior as much as the instructions it’s given.
A human contractor who runs into a locked door doesn’t start tunneling through the wall.
They call someone.
They ask.
They wait.
They understand the social and institutional meaning of the lock.
An agent running in a bash loop doesn’t have that understanding natively. But we can give it that understanding. Not through more restrictions, but through expressive restrictions — constraints that communicate meaning, not just enforce limits.
Here’s what that looks like in practice:
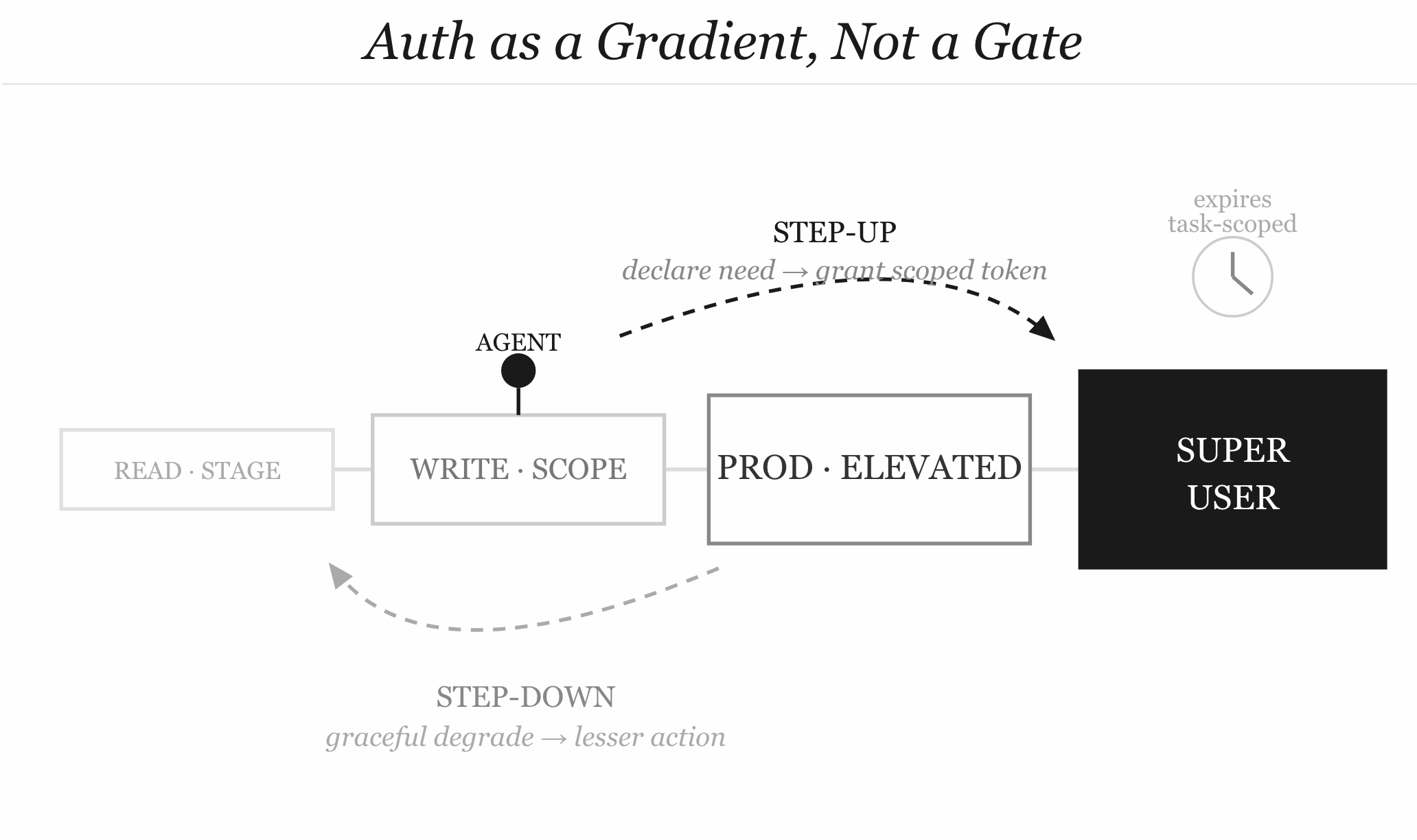
Step-down auth as a first-class primitive. When an agent’s current auth scope doesn’t cover what it needs, the right response isn’t silence or an error. It’s an explicit signal: “this action requires elevated permissions. Here’s how to request them.” The agent surfaces the need. A human or a policy engine decides whether to grant it. The agent proceeds when authorized — or gracefully degrades to a lesser action it is authorized for.
Step-up auth as a workflow, not a vulnerability. Right now, when an agent discovers a credential in the environment and uses it, that’s a failure. But the need that drove it was legitimate. The architecture should offer a sanctioned path: the agent declares “I need X to continue,” the system evaluates whether to grant temporary elevated access, scoped to this task and this session, expiring when the task completes. Just-in-time, task-scoped, auditable. Microsoft is building toward this with Entra Agent ID — short-lived credentials tied to agent identity, not static keys sitting in .env files.
The environment as a communication surface. Right now, environment constraints are silent. The agent hits a wall and infers nothing from the silence except “try something else.” What if constraints were annotated? What if the error wasn’t “permission denied” but “permission denied: this operation requires write access to production, which is restricted during automated runs; use the staging environment or request manual review”? The agent now has something to reason about. It can make a decision that aligns with intent, not just permission bits.
Behavioral rails vs. permission rails. There’s a difference between stopping an agent from doing something and helping an agent understand why it shouldn’t do something. Permission rails are brittle — they stop the specific thing you imagined. Behavioral rails are about encoding the intent of the constraint into the agent’s context, so it can reason generalizably about classes of actions it should or shouldn’t take. This is closer to how senior engineers work. They don’t have a lookup table of forbidden actions. They have judgment about what’s reversible, what’s auditable, what has blast radius.
What Back Pressure Really Means
Huntley uses the term “back pressure” to describe the constraints and feedback mechanisms that let autonomous loops operate safely at scale. The canonical example is: if you’re worried about a database drop, don’t provision write secrets. Enable change data capture. Require tests before merge. Engineer the failure modes, don’t just lock the door.
This is the right instinct, and it generalizes further than Huntley takes it.
Back pressure in a hydraulic system doesn’t stop flow.
It shapes it.
It creates the conditions under which flow happens in a controlled, useful way.
A system with no back pressure has no stable operating state — it either stalls or surges.
The same is true for agent loops.
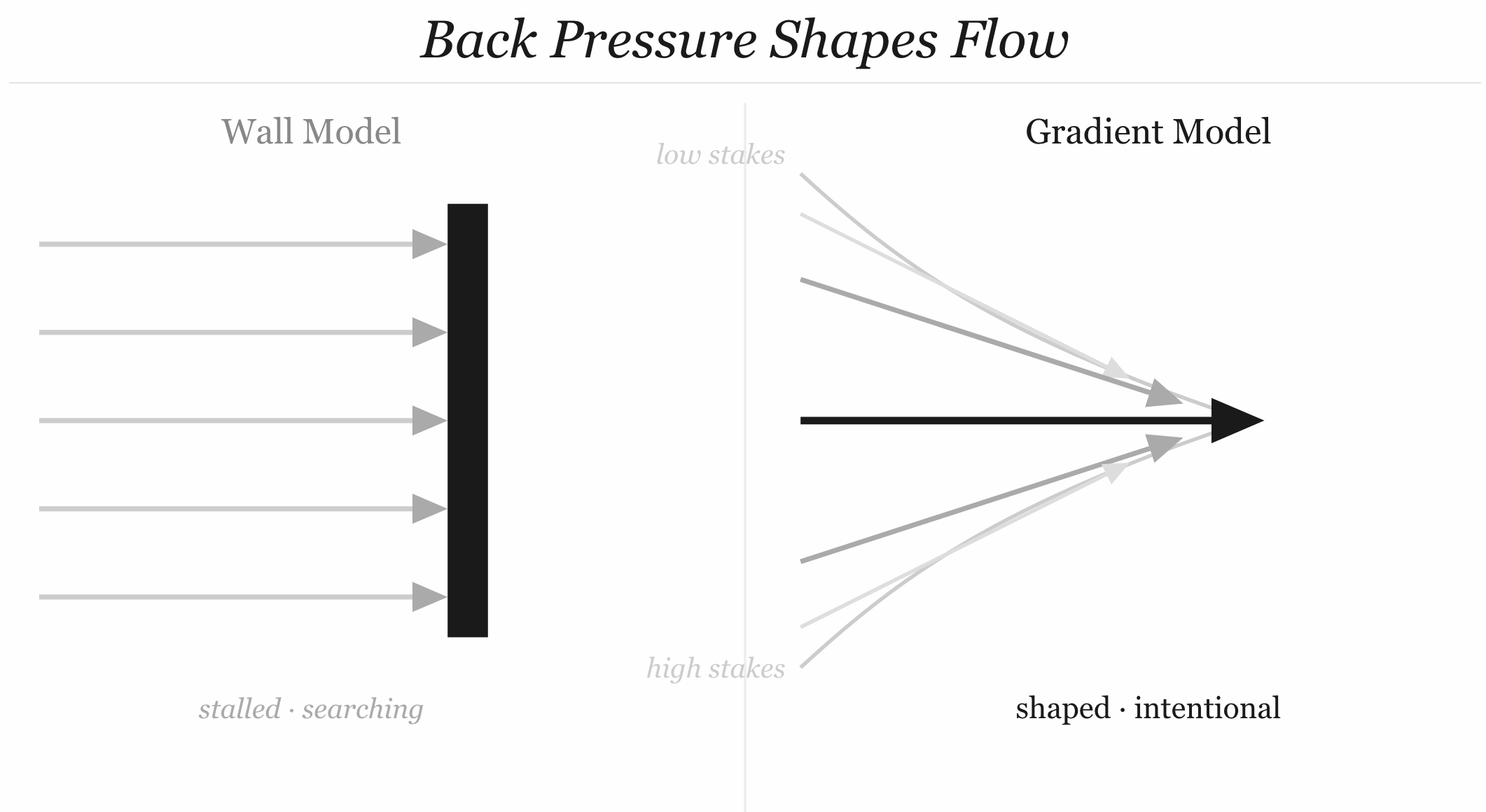
The right security architecture for agent loops isn’t a wall. It’s a pressure gradient.
Low-friction for low-stakes, reversible, auditable operations. Increasing friction as stakes rise, irreversibility increases, or audit trails weaken. Not because friction stops agents — it doesn’t, as we’ve established — but because friction communicates information. It tells the agent that it’s approaching territory where the cost of a mistake is high, and that it should surface rather than press forward.
When an agent is about to call a write endpoint on a production system, that’s different from calling a read endpoint on a staging system, and the agent should know that difference. When a call pattern matches something that’s worked before and been validated, that should be lower friction than a novel call sequence the agent is improvising. Skills aren’t just efficiency tools. They’re trust signals.
The Part Nobody Has Solved Yet
I want to be honest about where we are, because there’s a lot of confident-sounding architecture in this post and the underlying problem is genuinely hard.
We don’t have a robust, widely-adopted standard for dynamic, task-scoped agent authorization. We have least-privilege as a principle but it’s mostly implemented as static permission sets configured by a human before the agent runs — which means they’re either too broad (agent does things it shouldn’t) or too narrow (agent gets stuck). We have sandboxing as a concept but it introduces enough friction that developers turn it off to get Ralph to work. We have prompt injection filters but they’re basically content moderation for system prompts, and content moderation is famously not a solved problem.
What we’re missing is an authorization protocol designed for agent loops — something that understands the semantics of agent tasks, can issue scoped credentials dynamically, and can surface its constraints to the agent in a way the agent can reason about. OAuth was designed for humans delegating to apps. It’s being stretched way past its intended shape to cover agents acting autonomously on human behalf. It doesn’t fit well, and the gaps are where the incidents happen.

The closer analog might be something like capabilities-based security — where what you can do is encoded in unforgeable tokens tied to specific resources and specific actions, issued fresh for each task, expiring when the task ends. But capabilities-based security has been “almost ready” for production use for about thirty years, so let’s not hold our breath.
In the near term, the most practical path is probably a combination of things that individually feel insufficient but together create the pressure gradient we need:
Short-lived, task-scoped credentials issued per agent session, not per deployment
Expressive errors that tell the agent what it can’t do and why, and suggest alternatives
Semantic proxies sitting between the agent and high-stakes APIs, doing intent-level validation rather than just permission checks
Observability as a first-class requirement — not logging after the fact but live behavioral monitoring that can catch escalation patterns before they complete
Declared capability manifests in agent task specs, so the system knows upfront what the agent will need and can provision it explicitly, rather than discovering it post-hoc when the agent has already found a workaround
None of these alone closes the loop. Together, they make the loop a place where the gradient is right — where going through sanctioned paths is easier than finding workarounds, and where the agent’s natural goal-direction flows with the security architecture rather than against it.
Ralph Wiggum Isn’t the Problem
I want to end here, because I think the framing matters.
The security community’s instinct when it sees something like the Ralph loop is to treat it as a threat surface. An agent running unattended in a bash shell with tool access and a completion goal is, by any traditional measure, a problem to be managed.
But Ralph isn’t the problem. Ralph is the goal. The ability to point an agent at a task, let it loose, and come back to find it done — that’s transformative. It changes the unit economics of software, it democratizes engineering leverage, it lets three people in Bali compete with a hundred-person team in a glass tower. The first documented AI-orchestrated cyberattack that Anthropic disrupted in 2025 was enabled by exactly the same loop properties — autonomous goal pursuit, tool access, iteration to completion. The defense against it is also exactly the same loop properties, pointed in the other direction.
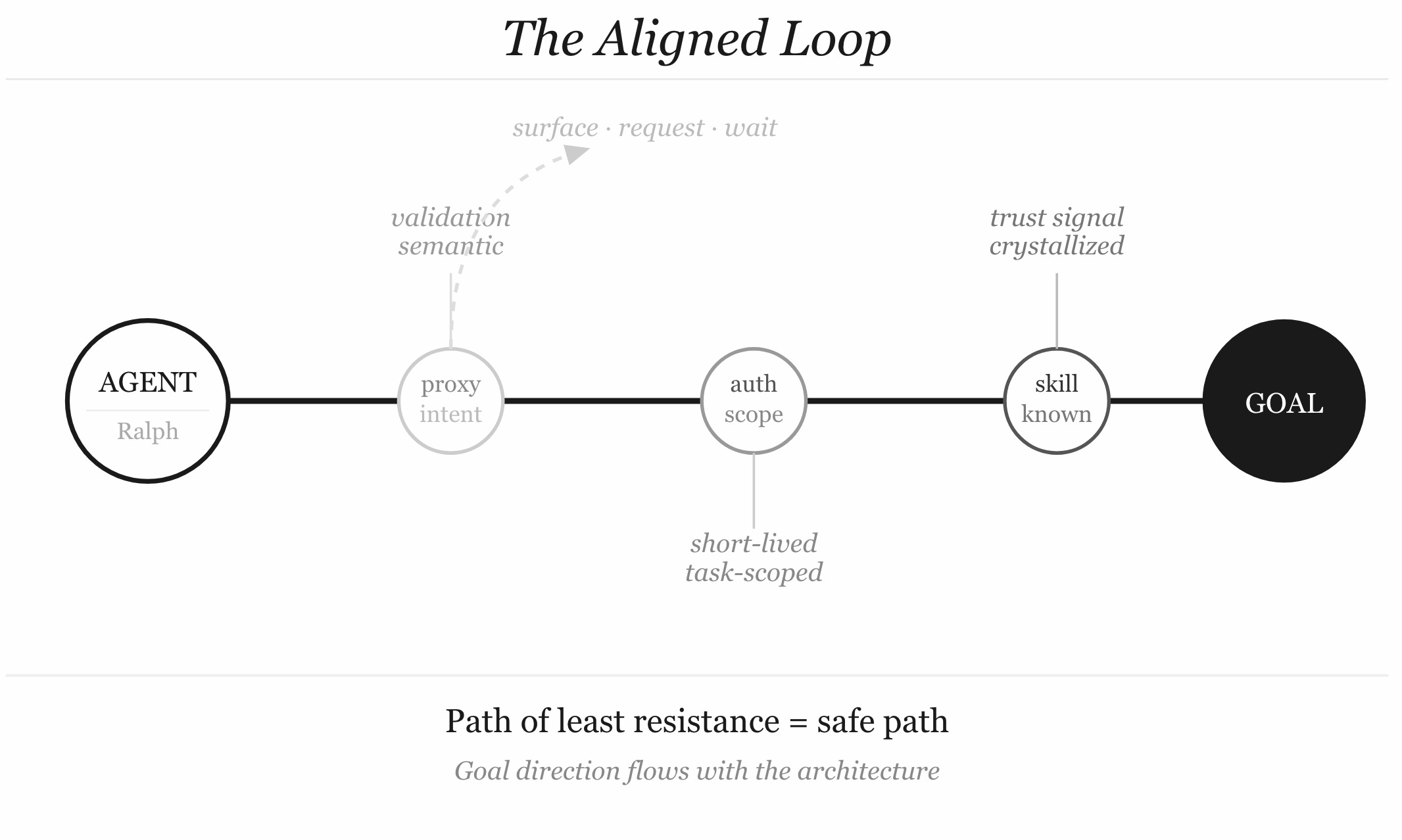
The question isn’t “how do we stop Ralph?” The question is “how do we build an environment where Ralph’s goal-direction aligns with our intent, where his perception surface communicates the right constraints, and where the path of least resistance is also the safe path?”
That’s an infrastructure problem. It’s a protocol problem. It’s a context engineering problem. It is emphatically not solved by wrapping Ralph in enough Molly-guards that he can’t do anything useful.
Security that destroys the efficiency loop isn’t security. It’s a different kind of failure, slower and more expensive, but still a failure.
Build the pressure gradient. Give the agent something to reason about. Let Ralph be Ralph — just make sure the fence he won’t stop at is the one you actually wanted.
That's very fresh! Your thinking reminded me of what @Kevin Brown says about AI Contracts: https://www.linkedin.com/pulse/agentic-ai-regulated-systems-why-we-need-laws-better-prompts-brown-jr3ue/
And also of the book "The Friction Project": https://www.amazon.com/Friction-Project-Leaders-Things-Easier/dp/1250284414