
The Context Window Has a Physics
On topology, gravity wells, and what the field is ignoring about how attention actually works

There’s a moment in every complex system where the intuitions you built up early become actively wrong. You hit a regime where the rules change and you don’t notice, because the thing still appears to work.
We are in that moment with context windows.
For two years the field has treated the context window as a container. You put things in. The model reads them. The model responds. If it forgets something, you make the window bigger. If it hallucinates, you add more context. The entire vocabulary of context management — “stuffing,” “chunking,” “retrieval,” “compaction” — is the vocabulary of container logistics. Load dock operations.
What nobody has written yet is this: the context window is not a flat container. It has a physics. Position is destiny inside it. Different regions behave differently. And the model’s attention — the actual computation that determines what gets used — is profoundly, structurally non-uniform.
This matters more than almost anything else in practical AI engineering right now. And the field is almost entirely unaware of it.
Start with something that sounds like a bug but is actually architecture.
In 2023, researchers from Stanford, UC Berkeley, and Samaya AI published a paper titled “Lost in the Middle: How Language Models Use Long Contexts.” They gave language models documents with relevant information planted at different positions and tested retrieval. The result was a U-shaped performance curve: models retrieved information most reliably from the beginning and end of context, and worst from the middle. The effect held across every model tested, regardless of context window size.
The first reaction was: training artifact. The second was: positional encoding issue. Fine-tune on longer documents and it goes away.
Neither was right.
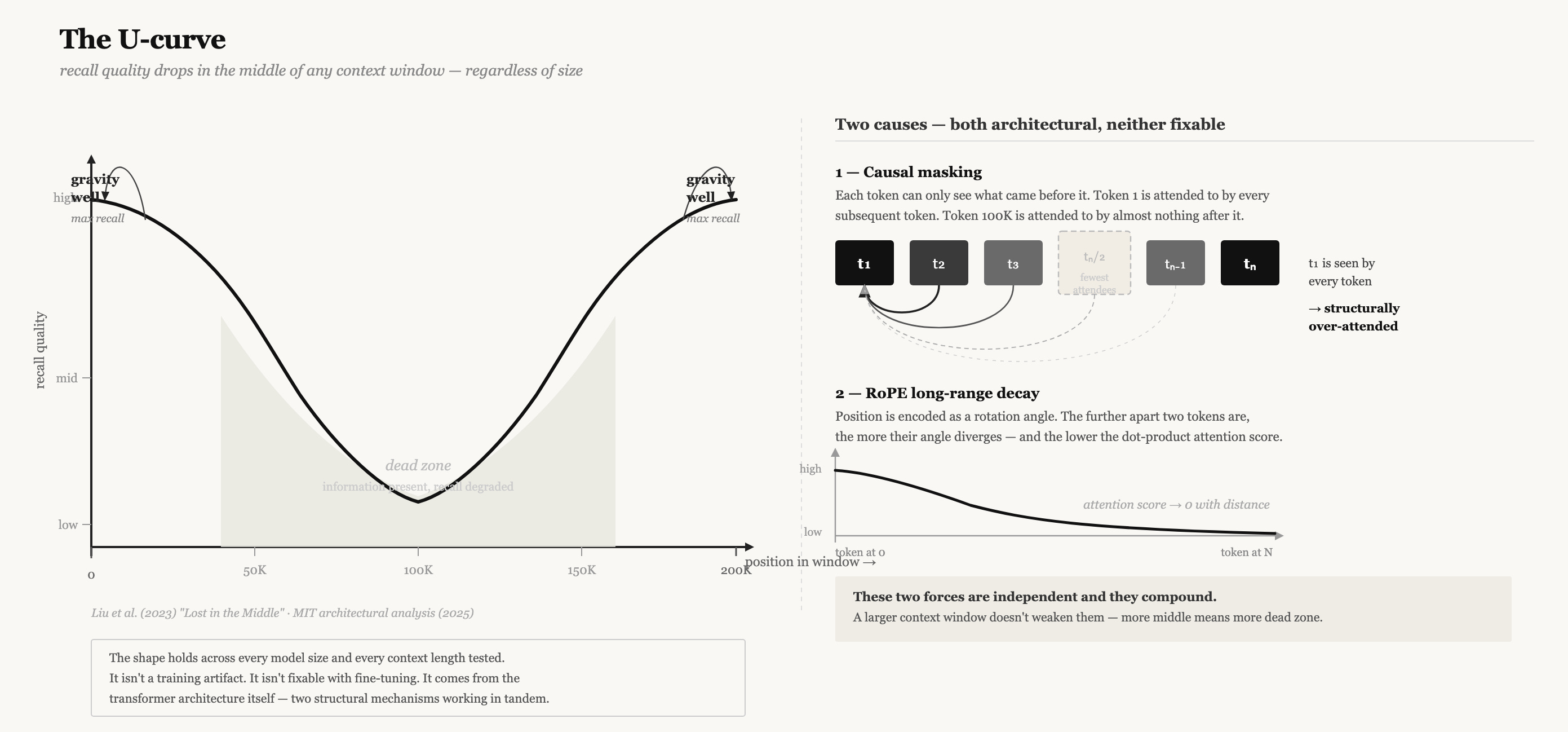
In 2025, MIT researchers traced the U-curve back to something structural — two things that are essentially built into the transformer architecture itself and can’t simply be trained away.
The first is causal masking. Every transformer language model generates left to right. Each token attends only to tokens before it, never after. This is fundamental to how they work — not an implementation choice but a requirement of the generation process. The consequence is asymmetric visibility. Token 1 is visible to every subsequent token. Token 50,000 is visible only to tokens that follow it. Across the whole forward pass, early tokens accumulate attention weight just by virtue of being early. They’re not more important. They’re just more attended to, structurally, because of when they exist.
The second is RoPE — Rotary Position Embedding, the positional encoding used in virtually every modern language model including Llama, Mistral, Gemma, and the models behind Claude and GPT-4. RoPE encodes position as a rotation in embedding space. The rotation for nearby tokens is small; for distant tokens it’s large. The consequence is a long-term decay effect: the attention score between two tokens decreases as their distance increases. Not a bug. A design choice with a legitimate purpose — it discourages attending to tokens that are far away, which during training was usually correct. In a context window of 2,048 tokens, this was fine. In a context window of 200,000 tokens, it means the middle 190,000 tokens are systematically deprioritized.
These two effects combine into something that doesn’t go away when you scale the window. A million-token context window doesn’t have less of this problem. It has more of it. There’s just more middle.
This is not like a caching problem where you fix the cache and performance goes up. This is more like asking why your parallel program has contention on shared state: the answer is inside the architecture. Understanding it is the prerequisite to engineering around it.
There’s a second phenomenon that’s been quietly accumulating in the mechanistic interpretability literature, and it has equally large practical implications.
Attention heads specialize.

The transformer uses multi-head attention — at each layer, multiple attention heads operate in parallel, each learning different linear projections of the query, key, and value matrices. The original paper framed this as a way for the model to attend to different aspects of the input simultaneously. That’s true but undersells what actually happens during training.
Different heads specialize in dramatically different functions. Some track syntactic structure. Some encode positional relationships. Some do factual recall — they’re the heads that activate when the model needs to retrieve a named entity or a memorized number. A class called “induction heads” (Olsson et al., 2022, one of the most cited papers in mechanistic interpretability) specifically tracks repetition: if a sequence [A][B] appeared earlier in context, induction heads help the model predict [B] when it sees [A] again. This is the mechanism behind in-context learning. Research from NeurIPS 2025 (”Head Pursuit,” Basile et al.) shows specialization extends further than previously known — individual heads reliably represent narrow semantic domains, and selectively editing as few as 1% of heads can suppress or enhance entire concept classes in model output.
There are also “iteration heads” — a recent discovery showing that some attention heads specifically enable chain-of-thought reasoning by performing iterative state updates across the sequence.
What this means for context engineering is something nobody has fully articulated yet: different kinds of information activate different specialist heads in the model. And the positional biases above apply differently to those specialists.
Induction heads, for instance, are specifically doing pattern-matching against earlier context. If you place information that you need the model to recognize as a pattern — examples, few-shot demonstrations, prior outputs to continue — in a region that induction heads are attending to, you get reliable recall. If you place it in the dead zone, you get silently degraded performance. You don’t get an error. You get drift.
This is not theoretical. Every production system that has hit unexplained quality degradation at some context utilization threshold is running into this. The developers look at their prompts and see all the information is there. The information is there. It’s just in the wrong gravitational zone for the computation being performed.
There is a third piece, which is the most recent and arguably the most important for infrastructure builders.
The KV cache.
During transformer inference, every input token generates a key vector and a value vector at each attention layer. These vectors are what other tokens attend to. As the context grows, the collection of all key and value vectors — the KV cache — grows linearly with it. For a modern large language model, this cache can consume 70% of total GPU memory during inference. At 32,000 tokens, we’re talking gigabytes per inference session, before you’ve even generated a response.
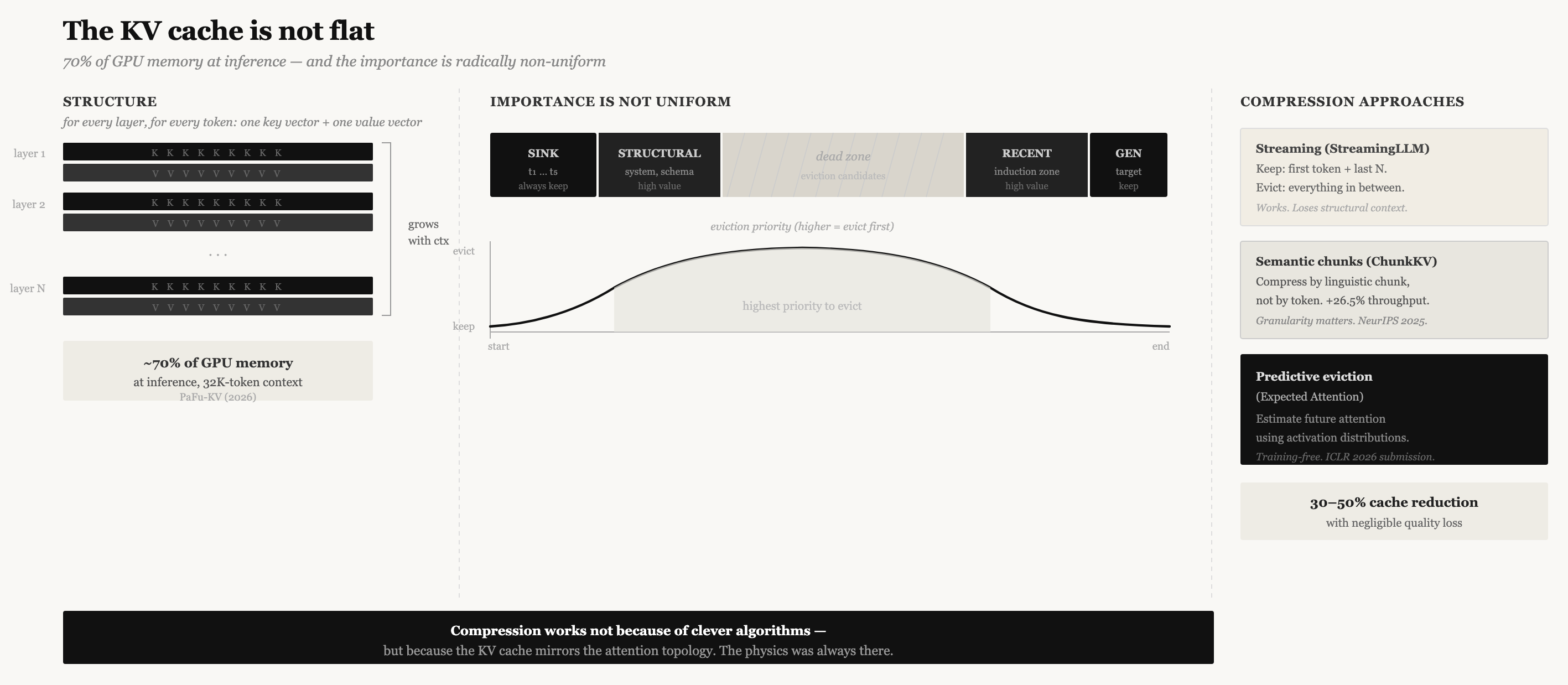
The naive approach is to keep the entire KV cache for the entire context. The slightly less naive approach, implemented by systems like StreamingLLM, is to keep the most recent tokens and the “attention sink” — the first token, which accumulates disproportionate attention weight and must be preserved to maintain generation coherence.
The research frontier has moved significantly beyond this. What’s emerging is a body of work that treats the KV cache not as a passive memory but as an object that can be compressed intelligently, using understanding of how attention actually works.
ChunkKV (NeurIPS 2025) observed that prior compression methods evaluated individual tokens for importance, which fragments semantic relationships. They proposed compressing at the level of semantic chunks — preserving complete linguistic structures rather than isolated tokens. This is a subtle but important shift: the unit of context isn’t the token, it’s the semantic chunk. Compressing at the wrong granularity destroys meaning even when the bits survive.
More remarkable is Expected Attention (submitted to ICLR 2026), which addresses a fundamental difficulty in KV cache compression: to know whether to evict a token’s cached vectors, you need to know whether future queries will attend to it. But future queries haven’t been generated yet. The paper’s resolution is to use the distributional properties of activations — the statistical regularities of how queries form in a given model — to estimate future attention in closed form. This is, effectively, predictive eviction: deciding what to keep based on a probabilistic model of what computation is about to happen.
The connection to the attention sink literature is direct. If the first token’s KV vectors are almost always attended to by everything, keep them regardless of content. If the last N tokens are almost always attended to by the immediately following generation, keep them. The middle — evaluate by estimated future importance.
The practical result in inference infrastructure: KV cache compression to 30-50% of full size with negligible quality loss. But the reason this works isn’t magic compression — it’s that the KV cache was never uniformly important in the first place. The physics was always there. We just didn’t have tools to exploit it.
Bring these three observations together and a coherent picture emerges.
The context window has topology. It’s not a flat address space where token 1 and token 100,000 are equivalent citizens. The beginning is a gravity well. The end is a gravity well. The middle is a low-attention zone, for reasons that have nothing to do with the quality of the information you put there. Different positions activate different specialist circuits in the model. The KV cache has a corresponding non-uniform importance structure that mirrors the attention structure.
In computer architecture, there’s a concept called NUMA — Non-Uniform Memory Access. In large multi-processor systems, memory access time depends on where the memory is physically located relative to which processor is asking for it. Code that ignores this runs correctly but slowly. Code written to be NUMA-aware — pinning threads near their data, accounting for access latency in data structure design — runs significantly faster. The underlying physics of memory doesn’t change. You’re just no longer ignoring it.

Context engineering today is NUMA-unaware. We stuff tokens into positions without modeling the topology. We retrieve document chunks and inject them wherever is convenient. We construct prompts without asking which specialist heads will process which sections, or whether the thing we most need the model to recall is in the gravitational dead zone.
The implication isn’t just theoretical. Every decision about context construction maps onto this topology: where examples go, where retrieved documents go, where tool outputs go, where the instruction goes. Getting this wrong doesn’t produce an error. It produces a model that technically has access to all the information and quietly uses less of it.
Jeff Hawkins spent much of “A Thousand Brains” arguing that the neocortex isn’t a uniform compute substrate — it’s organized into cortical columns, each running the same algorithm but on different inputs, building different reference frames and models of the world. The brain’s intelligence emerges not just from the algorithm but from the topology of how the algorithm is instantiated.
The same is true of the transformer, though less elegantly. The attention head is a cortical column in miniature. It learns a reference frame — a particular projection of query and key space that picks out a particular kind of relationship between tokens. There are hundreds of them in a large model, operating in parallel, each looking for its specialty. And what each finds is determined by where it looks, which is determined by position, which is non-uniform.
This is why thinking about context as a virtual machine, as I’ve written before, captures something real: the analogy holds because both are systems where what happens depends critically on where things are in memory, not just what they are. But the VM analogy doesn’t capture the specialist topology, the gravity wells, the way different operations have different access profiles. You need both to understand what you’re actually building against.
So what does NUMA-aware context engineering actually look like?
First, it means taking the U-curve seriously as a design constraint, not a quirk. The most critical information — the information failure to recall would break the task — should be at the beginning or end of context by default. Not because the model can’t see the middle, but because recall degrades there, and you are choosing to fight architectural physics or work with it. Working with it is free. Fighting it costs quality.
Second, it means thinking about what kind of cognitive operation each section of context needs to support. Few-shot examples that you need the model to generalize from activate induction heads — they benefit from being near content similar to what the model is about to generate. Configuration and structural constraints benefit from front-loading, which hits the model’s structural specialist heads under favorable positional conditions. Retrieved document chunks that serve as evidence can tolerate more middle placement if their relationship to the query is signaled clearly.
Third — and this is the infrastructure point — KV cache management is not separate from context quality. When you evict KV entries based on recency or length heuristics, you’re implicitly choosing which specialist heads’ computational work gets discarded. Recency-based eviction keeps induction-head-relevant material but discards attention-sink material at the front. Position-unaware eviction makes arbitrary tradeoffs across the specialist topology. Smart eviction — what Expected Attention and ChunkKV are building toward — needs a model of which KV entries are load-bearing for the current computation.
Fourth, compaction — the topic of my last post — looks different through this lens. When you summarize a long context into a shorter one, you’re not just reducing token count. You’re collapsing the topology. The summary starts fresh at position 1. The information it contains no longer has the positional relationships it had when it was built up incrementally. The model that reads the summary is navigating a different gravitational landscape than the model that built the original context. This is a real cost, not captured in “we preserved 95% of the information.” The arrangement of the information matters for how it’s used.
None of this means context windows are broken. They’re not. They’re doing remarkable things. But they are doing those things in a non-uniform space, and the engineering discipline around them has been ignoring the topology.
The good news is that this is a solvable class of problem. NUMA-aware programming exists and works. KV-cache-aware inference is a rapidly developing field. The attention head specialization literature is producing enough mechanistic clarity that designing for it is becoming tractable. The “lost in the middle” problem, now mechanistically understood, has engineering solutions that go beyond “don’t put important stuff in the middle.”
The less good news is that most of the tools in current use — prompt libraries, context management layers, RAG systems, compaction pipelines — were built without this model. They treat context as flat. They move information around without a physics.
That’s going to change, because the problems it causes are too consequential to ignore and the understanding needed to fix them is now, finally, at a level where it can be put to engineering use.
What This Means If You’re Building the Agentic Harness
The physics above isn’t just academic. It has direct consequences for how you construct the messages array every time you call the model.
Most agent harnesses build context the same way: append tool outputs to message history, grow the array, call the API, repeat. It works. Until it doesn’t. And when it stops working, the failure is silent — the agent loses a constraint it acknowledged earlier, re-tries an approach it already tried, or answers a question slightly wrong in a way that only surfaces three steps later. Nobody throws an error. The context just degraded.
Anthropic published their internal guidance on this in September 2025, and the framing they landed on is worth sitting with: “find the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome.” That sounds obvious. The topology above explains why it isn’t — because token count isn’t the only variable. Position is a variable too. Most harnesses treat context as a bag of tokens, not a manifold with shape.
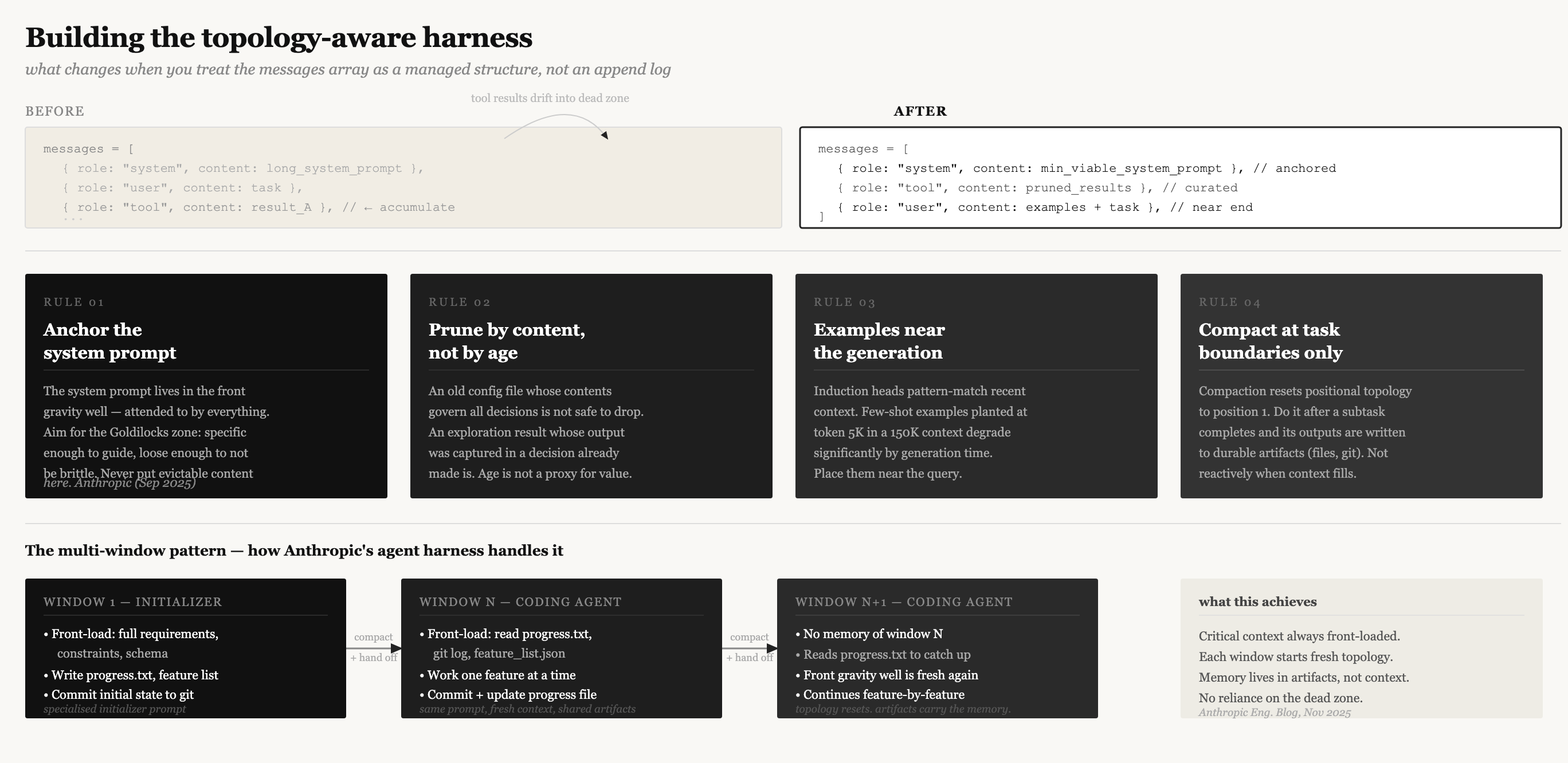
Anchor the system prompt — and keep it clean.
The system prompt occupies the front gravity well. It is the first thing in context, attended to by everything that follows it, and where the model’s factual and structural heads have maximum access. This is not the place for anything you might want to evict later. Anthropic’s published guidance describes two failure modes: over-specifying (hardcoded if-else logic that breaks on edge cases) and under-specifying (vague guidance that assumes shared context the model does not have). Both get worse as context grows and attention thins. Aim for the Goldilocks zone — specific enough to guide behavior, flexible enough to not be brittle.
Treat the messages array as a managed structure, not an append log.
The naive implementation is to push every tool result into the messages array and let it grow. This works until the accumulated tool history drifts into the dead zone — which is where the middle of any long array will end up. The things the agent did twenty turns ago are structurally deprioritized not because they are unimportant but because they are in positions that RoPE and causal masking both penalize.
The practical intervention is to prune tool results by semantic content, not by recency. A file read for exploration whose output was captured in a decision the agent already made is genuinely safe to drop. A configuration file read in turn 3 whose contents govern all subsequent decisions is not safe to drop even if it is old — it belongs front-loaded or re-injected, not left to drift.
Place few-shot examples near the generation target.
If you are using few-shot demonstrations, their position matters. Induction heads — the primary mechanism for in-context generalization — pattern-match against recent context to predict what comes next. They work best when the pattern they are matching is nearby. An example planted at the front of a 150K context, followed by 140K tokens of other material, has degraded induction signal by the time the model generates. The same example placed near the end of context — adjacent to the actual query — provides much stronger activation. This follows directly from the induction head mechanism (Olsson et al. 2022) and the positional topology described above.
Compact at task boundaries, not reactively.
Compaction — summarizing accumulated context and replacing it — resets positions to 1. The topology collapses: positional relationships between pieces of information are erased, and the model navigating the summary is navigating a different gravitational landscape than the model that built the original context. The right posture is not “compact when full.” It is “compact at a task boundary, after state has been persisted externally.” When the agent finishes a subtask, externalize what it learned — write to file, update the progress record, commit the change — then compact. At that point, the exploration history is genuinely safe to discard because everything it produced has been crystallized into durable artifacts.
The multi-window pattern
Anthropic’s November 2025 engineering post on long-running agents describes a concrete instance of this pattern. Long-horizon tasks — codebases, research projects, anything spanning hours — cannot complete in a single context window. The approach that works is a two-part harness: an initializer agent that front-loads a complete feature list, a progress file, and a git baseline into the first window; and a coding agent that starts every subsequent window by reading that progress file and git history rather than relying on memory that does not exist. Each new context window begins fresh. Its topology is intact. The front gravity well is available again. Memory lives in artifacts — in files the agent writes — not in context positions that will be evicted or forgotten.
None of this is exotic engineering. It is the discipline that follows from taking the physics seriously. The context window is not a neutral container. It has shape. Build accordingly.
References
Liu et al. (2023). “Lost in the Middle: How Language Models Use Long Contexts.” Stanford / UC Berkeley / Samaya AI. arXiv:2307.03172
Xiao et al. (2023). “Efficient Streaming Language Models with Attention Sinks.” MIT / Meta AI.
“When Attention Sink Emerges in Language Models.” ICLR 2025.
Basile et al. (2025). “Head Pursuit: Probing Attention Specialization in Multimodal Transformers.” NeurIPS 2025 Mechanistic Interpretability Workshop. arXiv:2510.21518
Olsson et al. (2022). “In-context Learning and Induction Heads.” Anthropic. arXiv:2209.11895
Liu et al. (2025). “ChunkKV: Semantic-Preserving KV Cache Compression for Efficient Long-Context LLM Inference.” NeurIPS 2025. arXiv:2502.00299
Devoto et al. (2025). “Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution.” Submitted to ICLR 2026.
Chen et al. (2024). “Found in the Middle: Addressing the Lost-in-the-Middle Problem via Multi-scale Positional Encoding (Ms-PoE).” arXiv:2403.04797
Merullo et al. (2024). “Talking Heads: Understanding Inter-layer Communication in Transformer Language Models.” NeurIPS 2024.
Su et al. (2021). “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864
Hawkins, J. (2021). A Thousand Brains: A New Theory of Intelligence. Basic Books.
Anthropic Engineering. (2025, Sep 29). “Effective Context Engineering for AI Agents.” anthropic.com/engineering/effective-context-engineering-for-ai-agents
Anthropic Engineering. (2025, Nov 26). “Effective Harnesses for Long-Running Agents.” anthropic.com/engineering/effective-harnesses-for-long-running-agents